The secret to refactoring code in baby steps
I am going to tell you a secret, that will probably make you more confident at tackling huge refactorings. It’s so simple, you probably did or saw this at some point already, but it’s easy to forget when you are knee deep into a refactoring. So here it is. The secret to doing huge refactorings in safe baby steps is: don’t immediately rip out old implementations. Instead use them as a crutch until it’s easy and safe to delete them.

There’s at least three techniques I know that lean on this insight: Parallel Change, Branch by Abstraction and Strangler Application. But before we get into these techniques in detail, let’s see what’s wrong with huge refactorings, when you do them the naive way.
It’s easy to get pulled into a rabbit hole with refactorings. What looks like it should be easy, gets increasingly more complicated as more and more parts of the codebase are affected by the change. These sort of changes are also commonly referred to as “shotgun surgery” because like the victim of a shotgun shooting they leave your codebase with lots of holes to heal.

In this state you cannot compile your code, integrate your change into the shared repository or start working on something new, which is bad. You may even have your manager lurking over your shoulder, asking for when you will be able to do something productive again and or even revert your changes, when you feel like you’re not making enough progress to finish the change in time.
What we should strive for instead is what Kent Beck called a resumable refactoring. The advantages are immediate: you can spend as little or much time on these refactorings as you have available. Instead of having a huge task of undefined length, you can just do a bit of refactoring here and there and integrate it much more nicely into more visibly productive work.
This will allow you to tackle huge beasts of refactorings, even under time pressure and incrementally refactor things with your whole team just by applying the boy scout rule.
Parallel change
This technique is often used to introduce breaking changes in APIs without immediatley breaking existing users. The basic Idea is to keep the old implementation around for a period of time until it is no longer in use. If you ever saw a method in a public API marked as deprecated you probably saw this technique in action. This method works even better when you use it in your own code base, because you are in control of both the caller as well as the callee.
Parallel change example
Let’s say you want to move from your own proprietary logging tool to something like Log4J. Because your old logging call takes three arguments and the new tool only takes two, you are stuck rewriting each and every call to the logging library in your code base. How would you approach this with Parallel change?
Start by marking the old logging method as deprecated.
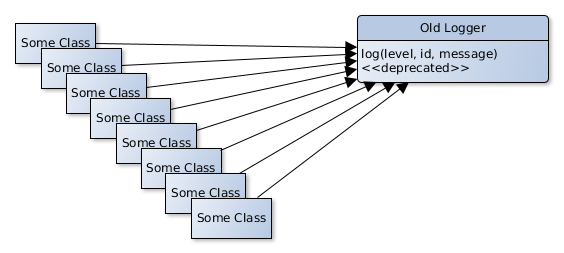
Now we can introduce the new class and method to do logging and start using this method to log things for any new code we write, rerouting the calls to the old logging method as we go along. The compiler or even the IDE will show as where we have a refactoring in progress by highlighting the deprecated method calls. Now by applying the boy scout rule everyone in your team will rewrite the old log call when they see one.
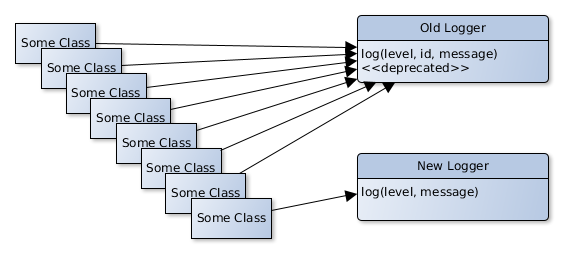
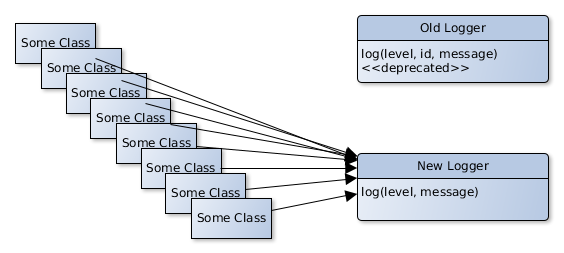
As soon as all the log calls are using the new logger class, we can simply and safely delete the old implementation. Shotgun surgery succeeded!
Branch by Abstraction
Branch by abstraction started out as an alternative to introducing branches in your SCM and keeping the rest of the code base integrated, when you are just replacing one class or module. A common case is to replace something like your homegrown ORM with something that’s open source.
Branch by Abstraction Example
Let’s say you want to remove the dependency on your homegrown ORM and replace it with Hibernate.
First we introduce an abstraction that captures the essence of what this object does, so in our case it’s a Repository in the terminology of Domain-Driven Design.
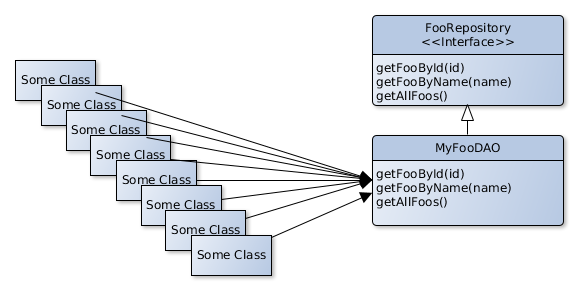
Now we can start moving all the users to the new FooRepository interface. It may also help to, again, mark the old type (MyFooDAO) as deprecated so we can see all the references to the type at a glance. If we heavily rely on Dependency Injection we will also likely already have this abstraction.
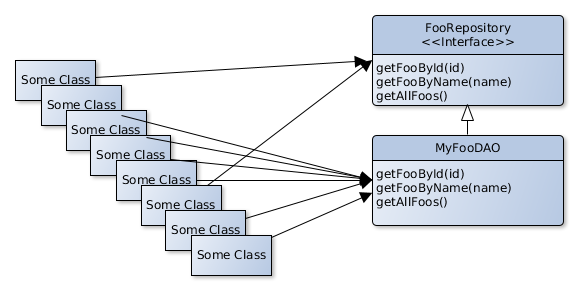
We can already start implementing the new HibernateRepository now. Also note that the abstraction enables us to use both implementations in production and see if they behave the same way. This may give us the confidence we need in order to switch from the old implementation to the new one because we made sure both behave the same way in production. That’s especially important when the behaviour of the class being replaced is not well understood, documented and has lots of edge cases.
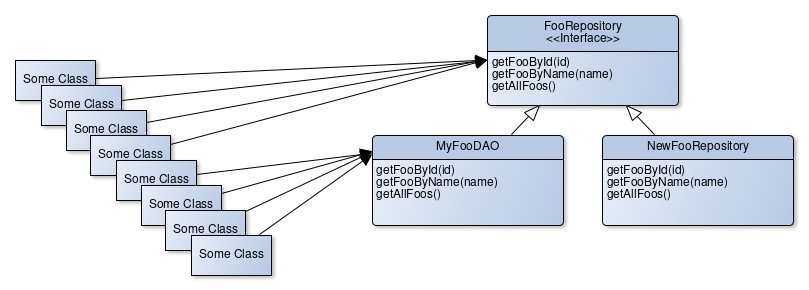
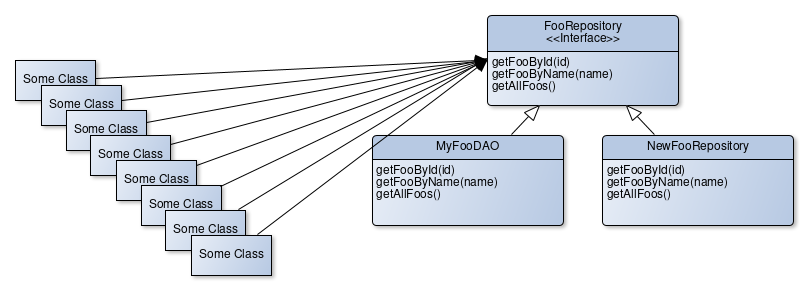
Once we get to the point where all the consumers are relying on the abstraction instead of the implementation, it’s safe to delete the old implementation. But we might choose to keep it around for some time, just in case we notice a huge flaw in our new implementation.
In praise of incrementalism
Each of these techniques it not without issues. For branch by abstraction you need to first find the “pinch point” where introducing an abstraction makes sense. And for both techniques things can get out of hand quickly if you start doing too many changes at the same time, so use these techniques with caution.
That said, I found that using these techniques incredibly valuable in my daily work. In one project I worked with we both replaced the logging library by using Parallel Change and switch our Frontend from pre-compiled HTML with placeholders to Handlebars templates by using Branch by Abstraction, collectively within a few months. We basically redid our entire Frontend Architecture without a rewrite. If you try it, let me know what you think on Twitter.